Bảo Mật GitHub Agentic Workflows: 4 Nguyên Tắc Chạy Coding Agents An Toàn Trong CI/CD
GitHub công bố kiến trúc bảo mật chi tiết cho Agentic Workflows — không chỉ là lý thuyết, mà là 4 controls cụ thể: defense in depth, zero-secret agents, staged writes và comprehensive logging. Đây là mô hình mọi team cần study trước khi deploy agents vào production.
TL;DR
GitHub vừa công bố chi tiết kiến trúc bảo mật đằng sau GitHub Agentic Workflows. Điểm cốt lõi: agentic workflows chỉ hữu ích trong production nếu được bao bọc bởi infrastructure-level controls, không phải prompt-level trust. Bốn nguyên tắc thiết kế: defense in depth, không giao secrets cho agents, stage tất cả writes, và log mọi thứ.
Hứa hẹn của coding agents thật hấp dẫn: wake up buổi sáng và thấy tests đã chạy, refactors đã xong, repo fixes đã sẵn sàng review. Nhưng khi bạn thực sự deploy agents vào CI/CD production, thực tế phức tạp hơn nhiều.
Vấn đề: AI agents là non-deterministic. Chúng consume untrusted inputs. CI/CD environments vốn đã permissive by design. Khi bạn kết hợp hai thứ này lại — permissive automation với untrusted agent behavior — blast radius khi something goes wrong trở nên rất lớn.
GitHub đã publish một bài viết kỹ thuật chi tiết về cách họ giải quyết bài toán này trong GitHub Agentic Workflows. Đây không phải generic AI safety commentary — đây là security engineering thực tế bạn có thể học hỏi để thiết kế agent stack của riêng mình.
Threat Model Bạn Cần Adopt
Theo GitHub Blog:
"We assume an agent will try to read and write state that it shouldn't, communicate over unintended channels, and abuse legitimate channels to perform unwanted actions."
Đây là threat model đúng đắn. Không phải vì agents "xấu" — mà vì chúng non-deterministic và dễ bị prompt injection. Hai properties thay đổi toàn bộ threat model:
- Agents có thể reason và act autonomously — điều này khiến chúng valuable, nhưng cũng có nghĩa không thể trust by default khi gặp untrusted inputs
- GitHub Actions là permissive environment — shared trust domain là feature tốt cho deterministic automation, nhưng nguy hiểm khi kết hợp với untrusted agent behavior
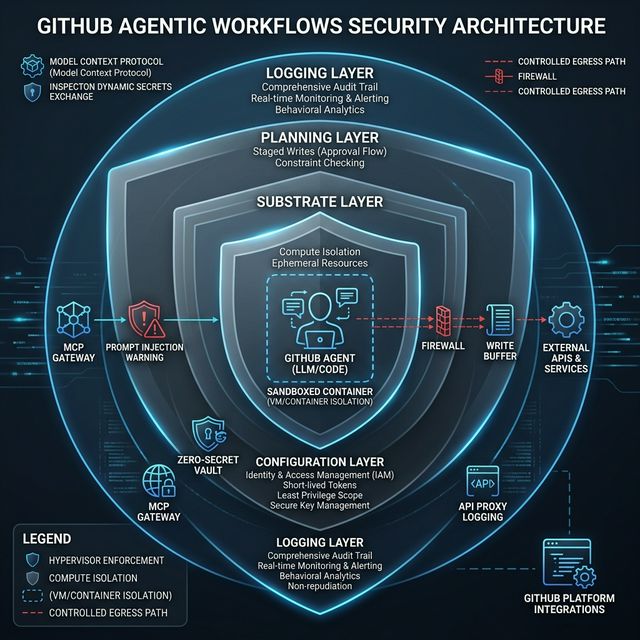
Defense-in-depth: 3 layers bảo vệ agent khỏi prompt injection, secret leakage và rogue writes
Nguyên Tắc 1: Defense in Depth
GitHub Agentic Workflows có kiến trúc 3 layers:
Substrate Layer
Nền tảng: GitHub Actions runner VM và trusted containers. Cung cấp:
- Isolation giữa các components
- Mediation của privileged operations và system calls
- Kernel-enforced communication boundaries
Quan trọng: Những protections này hold ngay cả khi một untrusted user-level component bị compromise và execute arbitrary code trong container boundary.
Configuration Layer
Tầng declarative artifacts — dictates:
- Những components nào được load
- Components kết nối với nhau như thế nào
- Communication channels nào được phép
- Externally minted tokens (agent API keys, GitHub access tokens) được load vào containers nào
Configuration layer là nơi token placement được kiểm soát — quyết định secrets đến được hands nào.
Planning Layer
Tầng cao nhất: tạo staged workflow với explicit data exchanges giữa các stages. Safe outputs subsystem là instance quan trọng nhất của secure planning — kiểm soát những gì agent có thể write.
Tại sao layered controls tốt hơn single safety switch? Vì mỗi layer giả định layer trên có thể bị bypass. Defense in depth đảm bảo failures ở một layer không collapse toàn bộ hệ thống.
Nguyên Tắc 2: Zero-Secret Agents
Đây là nguyên tắc táo bạo nhất: agents không được phép nhìn thấy bất kỳ secret nào.
Vấn đề với mô hình cũ: trong GitHub Actions, sensitive material như agent authentication tokens và MCP server API keys thường ở environment variables và config files visible to all processes trong VM. Một agent bị prompt-injected có thể:
- Đọc configuration files, SSH keys, Linux
/procstate, workflow logs để tìm credentials - Upload secrets lên web hoặc encode chúng trong GitHub objects (issues, PRs, comments)
Giải pháp của GitHub:
Agent Container (sandboxed)
│
├── [MCP access] → MCP Gateway (separate trusted container)
│ └── Has exclusive access to MCP auth material
│
├── [LLM calls] → API Proxy (isolated)
│ └── LLM auth tokens stored here, not exposed to agent
│
└── [Internet] → Firewall
└── Private network giữa agent và firewall
Agent communicate với LLM qua API proxy — tokens được đặt trong proxy, agent không bao giờ thấy chúng trực tiếp.
Để xử lý host file system: GitHub mount toàn bộ VM host file system read-only tại /host, overlay selected paths với empty tmpfs layers, và launch agent trong chroot jail rooted tại /host.
Trade-off: Zero-secret agents yêu cầu đánh đổi convenience lấy safety. Coding workloads cần broad access — nhưng expanding in-container setup sẽ duplicate existing provisioning logic và tăng network destinations cần cho phép qua firewall.
Nguyên Tắc 3: Stage and Vet All Writes
Ngay cả khi agent không có secrets, nó vẫn có thể gây hại. Ví dụ: spam repository với pointless issues và PRs, hoặc thêm objectionable URLs vào objects.
Safe Outputs Pipeline:
Agentic workflows compiler decompose workflows thành explicit stages. Mỗi stage định nghĩa:
- Active components và permissions (read vs. write)
- Data artifacts emitted bởi stage đó
- Admissible downstream consumers của artifacts
Khi agent chạy:
- Agent chỉ có thể read GitHub state qua GitHub MCP server
- Agent chỉ có thể stage updates qua safe outputs MCP server
- Sau khi agent exit, buffered write operations được xử lý qua suite of safe outputs analyses
Ba controls của Safe Outputs:
- Allowlist: Workflow author specify write operations nào được phép (create issues, comments, PRs...)
- Rate limiting: Giới hạn số lượng updates (ví dụ: tối đa 3 PRs mỗi run)
- Content sanitization: Analyze và remove unwanted patterns (URL stripping, objectionable content)
Chỉ artifacts pass qua toàn bộ pipeline mới được passed on.
Nguyên Tắc 4: Log Everything
"Agents are determined to accomplish their tasks by any means and have a surprisingly deep toolbox of tricks for doing so."
Ngay cả với zero secrets và vetted writes, agents vẫn có thể behave unexpectedly. Post-incident analysis cần visibility vào complete execution path.
GitHub log ở mọi trust boundary:
- Firewall layer: Network và destination-level activity
- API Proxy: Model request/response metadata và authenticated requests
- MCP Gateway và MCP Servers: Tool invocations
- Agent Container: Potentially sensitive actions như environment variable accesses
Kết quả: end-to-end forensic reconstruction, policy validation, và rapid detection của anomalous behavior.
GitHub còn mention: logging cũng lay foundation cho future information-flow controls — mọi điểm có thể observe communication cũng là điểm có thể mediate nó.
Reference Architecture Cho Teams Tự Xây
Nếu bạn không dùng GitHub stack nhưng muốn borrow patterns:
┌─────────────────────────────────────────┐
│ Isolated Container │
│ │
│ Agent Runtime (chroot / VM) │
│ │ │
│ ├─ Read: GitHub/Repo state │
│ └─ Stage writes (buffered) │
│ │
└────────────────┬────────────────────────┘
│
┌────────────┼────────────┐
│ │ │
MCP Gateway API Proxy Firewall
(tool auth) (LLM tokens) (egress control)
│
Safe Outputs Pipeline
├── Allowlist (which ops are permitted)
├── Rate limits (max writes per run)
└── Content sanitization
│
Central Audit Log
│
GitHub / Jira / Slack / etc.
Checklist Tối Thiểu Trước Khi Deploy Agents
- Isolated execution boundary: Agent chạy trong container/VM riêng biệt với controlled egress
- No direct secret access: Secrets được đặt trong proxy/gateway, agent không nhìn thấy trực tiếp
- Approved tool gateways: Tool access qua trusted gateway, không phải direct
- Write buffering và moderation: Agent stage writes trước, có pipeline vet content trước khi thực sự write
- Audit logs across trust boundaries: Log tại mọi điểm communication
- Không rely vào prompt instructions alone: Infrastructure controls, không phải "please don't do X" trong system prompt
Takeaway
"The future is not 'more powerful agents,' it is 'more governable agents.'"
Khi evaluate bất kỳ agent platform nào, hãy hỏi 4 câu:
- Agents chạy trong isolated environment chưa?
- Secrets được protect như thế nào — agents có nhìn thấy trực tiếp không?
- Writes được vetted và rate-limited chưa?
- Có audit logs đầy đủ tại mọi trust boundary không?
Nếu câu trả lời là "chúng ta tin vào system prompt" — đó là dấu hiệu cần thiết kế lại.