GPT-5.4 mini & nano: Designing Faster, Cheaper Coding Subagents Without Losing Quality
OpenAI just released GPT-5.4 mini and nano — small models optimized for coding workflows and subagents. Here's how to redesign your pipeline using the planner-worker pattern to cut latency and cost.
TL;DR
OpenAI released GPT-5.4 mini and nano on March 17, 2026 — small models running 2x faster than GPT-5 mini, specifically optimized for coding workflows and subagents. The planner-worker pattern — GPT-5.4 plans, mini/nano execute in parallel — reduces both latency and cost without sacrificing quality.
One of the most practical problems in building AI coding tools: you don't need the largest model for every step.
Codebase search? Targeted diff? Unit test fix? These are repetitive, clearly bounded tasks that don't need full reasoning power of a flagship model.
That's exactly why OpenAI shipped GPT-5.4 mini and nano.
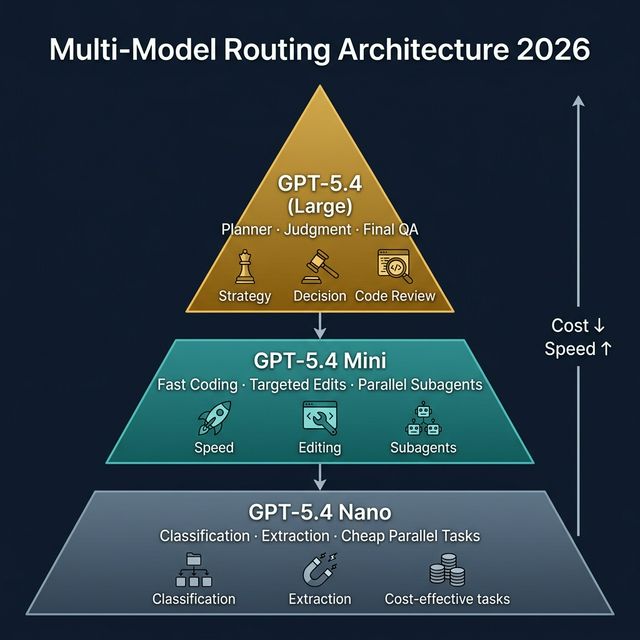
What's Actually New
According to the OpenAI announcement (March 17, 2026):
"GPT-5.4 mini significantly improves over GPT-5 mini across coding, reasoning, multimodal understanding, and tool use, while running more than 2x faster. It also approaches the performance of the larger GPT-5.4 model on several evaluations, including SWE-Bench Pro."
GPT-5.4 mini:
- 2x faster than GPT-5 mini
- Near GPT-5.4-level on SWE-Bench Pro and OSWorld-Verified
- Best for: targeted edits, codebase navigation, front-end generation, debugging loops
- Max reasoning effort:
high
GPT-5.4 nano:
- Smallest, cheapest GPT-5.4 variant
- Recommended for: classification, data extraction, ranking, simple coding subagents
- Not a mini replacement — a separate tier for specific tasks
Planner-worker pattern: GPT-5.4 plans, mini/nano subagents execute in parallel
API Pricing
| Model | Input | Output | Context |
|---|---|---|---|
| GPT-5.4 mini | $0.75 / 1M tokens | $4.50 / 1M tokens | 400k |
| GPT-5.4 nano | $0.20 / 1M tokens | $1.25 / 1M tokens | — |
| GPT-5.4 (large) | $5 / 1M tokens | $25 / 1M tokens | — |
In Codex: GPT-5.4 mini uses only 30% of the GPT-5.4 quota — roughly 3x more cost-efficient for simpler tasks.
Mini vs Nano: When to Use Each
| Task | Mini | Nano |
|---|---|---|
| Targeted file edits | ✅ Best | ❌ May miss context |
| Codebase search + summarize | ✅ | ⚠️ Small files only |
| Debugging loops | ✅ | ❌ |
| Front-end code generation | ✅ | ❌ |
| Classification / labeling | ⚠️ Overkill | ✅ Best |
| Data extraction / ranking | ⚠️ | ✅ |
| Simple code edits (1-5 lines) | ⚠️ | ✅ |
| Complex unit test fixes | ✅ | ❌ |
| Screenshot interpretation | ✅ | ❌ |
Rule of thumb: Use nano for tasks with clearly bounded input/output. Use mini when light reasoning or code generation is needed.
Planner-Worker Architecture
The pattern OpenAI explicitly describes in the announcement:
GPT-5.4 (Planner)
|
|-- Analyze request
|-- Break into subtasks
|-- Assess per-task complexity
+-- Route to mini/nano subagents
|
|-- mini: search codebase
|-- mini: review large file
|-- mini: generate targeted diff
+-- nano: classify error type
"In Codex, a larger model like GPT-5.4 can handle planning, coordination, and final judgment, while delegating to GPT-5.4 mini subagents that handle narrower subtasks in parallel." — OpenAI
Practical Workflow Recipe
Step 1: Planner analyzes and creates task graph
Use full GPT-5.4 for planning — this is where reasoning depth matters most.
Step 2: Classify subtask type and select model
def select_model(task_type: str) -> str:
nano_tasks = ["classify", "extract", "rank", "simple_edit"]
mini_tasks = ["search", "diff", "debug", "generate", "review_file"]
if task_type in nano_tasks:
return "gpt-5.4-nano"
elif task_type in mini_tasks:
return "gpt-5.4-mini"
return "gpt-5.4"
Step 3: Run subtasks in parallel
import asyncio
async def run_subtasks(task_graph):
tasks = [
execute_with_model(subtask, select_model(subtask.type))
for subtask in task_graph.subtasks
]
return await asyncio.gather(*tasks)
Step 4: Planner aggregates and produces final output
Full GPT-5.4 reviews all subagent results before final delivery.
Step 5: Retry with model fallback
async def execute_with_retry(subtask, model, fallback="gpt-5.4"):
try:
return await execute_with_model(subtask, model)
except QualityCheckFailed:
return await execute_with_model(subtask, fallback)
Cost/Performance Checklist
- Choose the smallest model that passes your quality bar — test each task type independently
- Measure latency per step, not just total — bottlenecks are often in tool calls
- Shadow evaluation — run mini alongside GPT-5.4 on 5-10% of traffic before full migration
- Track tool-call overhead separately — real latency = model time + code execution time
- Set explicit quality thresholds before enabling auto-fallback
Common Pitfalls
Over-delegating to nano: Strong for classification, weak for multi-step reasoning. Don't hand it complex debugging.
Poor prompt boundaries: Mini/nano need focused prompts. Excess context degrades quality more with smaller models.
Ignoring tool-call overhead: A subagent running code execution can take more wall-clock time than model latency. Measure both.
Migrating everything at once: Start with one pipeline, measure results, then expand gradually.
Availability
- GPT-5.4 mini: API (400k context), Codex (app/CLI/IDE/web), ChatGPT (Free and Go users via "Thinking")
- GPT-5.4 nano: API only —
$0.20/$1.25per 1M tokens
FAQ
Does GPT-5.4 mini replace GPT-5 mini? Per OpenAI: yes — it consistently outperforms GPT-5-mini at similar latencies. Migration is recommended.
Can nano handle tool calling? Yes, but reliability is lower than mini for complex tool chains. Best for single-tool calls with simple inputs.
Does Codex automatically use mini subagents? Yes — in Codex you can configure delegation to mini subagents. Mini uses 30% of the GPT-5.4 quota.