GitHub Agentic Workflows Security: 4 Principles for Running Coding Agents Safely in CI/CD
GitHub published the detailed security architecture behind Agentic Workflows — not theory, but 4 concrete controls: defense in depth, zero-secret agents, staged writes, and comprehensive logging. Every team should study this model before deploying agents to production.
TL;DR
GitHub published detailed security architecture for GitHub Agentic Workflows. The core insight: agentic workflows are only useful in production if bounded by infrastructure-level controls, not prompt-level trust. Four design principles: defense in depth, don't trust agents with secrets, stage and vet all writes, and log everything.
The promise of coding agents is compelling: wake up each morning to tests run, refactors completed, repo fixes staged for review. But when you actually deploy agents into production CI/CD, the reality is considerably more complex.
The problem: AI agents are non-deterministic. They consume untrusted inputs. CI/CD environments are permissive by design. Combine these — permissive automation with untrusted agent behavior — and the blast radius when something goes wrong becomes enormous.
GitHub published a detailed technical writeup on how they solved this problem in GitHub Agentic Workflows. This isn't generic AI safety commentary — it's real security engineering you can apply to your own agent stack.
The Threat Model You Need to Adopt
From the GitHub Blog:
"We assume an agent will try to read and write state that it shouldn't, communicate over unintended channels, and abuse legitimate channels to perform unwanted actions."
This is the correct threat model. Not because agents are malicious — but because they're non-deterministic and susceptible to prompt injection. Two properties change the entire threat model:
- Agents can reason and act autonomously — this makes them valuable, but also means they can't be trusted by default when exposed to untrusted inputs
- GitHub Actions is a permissive environment — shared trust domain is a feature for deterministic automation, but dangerous when combined with untrusted agent behavior
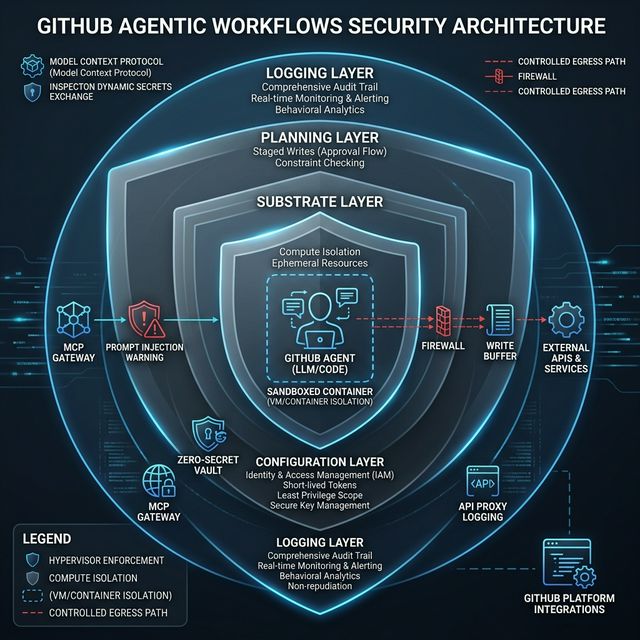
Defense-in-depth: 3 layers protecting agents from prompt injection, secret leakage, and rogue writes
Principle 1: Defense in Depth
GitHub Agentic Workflows uses a 3-layer architecture:
Substrate Layer
The foundation: GitHub Actions runner VM and trusted containers. Provides:
- Isolation between components
- Mediation of privileged operations and system calls
- Kernel-enforced communication boundaries
Critical: These protections hold even if an untrusted user-level component is compromised and executes arbitrary code within its container isolation boundary.
Configuration Layer
The declarative artifacts layer — dictates:
- Which components are loaded
- How components connect to each other
- Which communication channels are permitted
- Where externally minted tokens (agent API keys, GitHub access tokens) land
The configuration layer controls token placement — determining which secrets reach which hands.
Planning Layer
The highest layer: creates a staged workflow with explicit data exchanges between stages. The safe outputs subsystem is the primary instance of secure planning — controlling what the agent can actually write.
Why layered controls beat a single safety switch: Each layer assumes the layer above it may be bypassed. Defense in depth ensures failure at one layer doesn't collapse the entire system.
Principle 2: Zero-Secret Agents
This is the boldest principle: agents must have zero access to secrets.
The problem with the classic model: in GitHub Actions, sensitive material like agent auth tokens and MCP server API keys live in environment variables and config files visible to all processes on the VM. A prompt-injected agent could:
- Read config files, SSH keys, Linux
/procstate, workflow logs to discover credentials - Upload secrets to the web or encode them in public GitHub objects (issues, PRs, comments)
GitHub's solution:
Agent Container (sandboxed)
|
|-- [MCP access] --> MCP Gateway (separate trusted container)
| Has exclusive access to MCP auth material
|
|-- [LLM calls] --> API Proxy (isolated)
| LLM auth tokens stored here, never exposed to agent
|
+-- [Internet] --> Firewall
Private network between agent and firewall
Agent communicates with the LLM through an API proxy — tokens live in the proxy, the agent never sees them directly.
For host file system access: GitHub mounts the entire VM host file system read-only at /host, overlays selected paths with empty tmpfs layers, and launches the agent in a chroot jail rooted at /host.
The trade-off: Zero-secret agents require sacrificing some convenience for safety. Coding workloads need broad access — but expanding in-container setup would duplicate existing provisioning logic and increase the network destinations that must be allowed through the firewall.
Principle 3: Stage and Vet All Writes
Even without secrets, a rogue agent can still cause harm. For example: spam a repository with pointless issues and PRs, or embed objectionable URLs in repository objects.
The Safe Outputs Pipeline:
The agentic workflows compiler decomposes workflows into explicit stages. Each stage defines:
- Active components and permissions (read vs. write)
- Data artifacts emitted by that stage
- Admissible downstream consumers of those artifacts
During agent execution:
- Agent can only read GitHub state via the GitHub MCP server
- Agent can only stage updates via the safe outputs MCP server
- After the agent exits, buffered writes are processed through the safe outputs analysis suite
Three safe outputs controls:
- Allowlist: Workflow authors specify which write operations are permitted (create issues, comments, PRs...)
- Rate limits: Cap the number of updates allowed (e.g., at most 3 PRs per run)
- Content sanitization: Analyze and remove unwanted patterns (URL stripping, objectionable content removal)
Only artifacts passing the entire pipeline are passed on.
Principle 4: Log Everything
"Agents are determined to accomplish their tasks by any means and have a surprisingly deep toolbox of tricks for doing so."
Even with zero secrets and vetted writes, agents can still behave unexpectedly. Post-incident analysis requires visibility into the complete execution path.
GitHub logs at every trust boundary:
- Firewall layer: Network and destination-level activity
- API Proxy: Model request/response metadata and authenticated requests
- MCP Gateway and MCP Servers: Tool invocations
- Agent Container: Potentially sensitive actions like environment variable accesses
Together, these logs support end-to-end forensic reconstruction, policy validation, and rapid detection of anomalous behavior.
GitHub also notes: pervasive logging lays the foundation for future information-flow controls — every point where communication can be observed is also a point where it can be mediated.
Reference Architecture for Teams Building Their Own Stack
If you're not using GitHub's stack but want to borrow the patterns:
+------------------------------------------+
| Isolated Container |
| |
| Agent Runtime (chroot / VM) |
| | |
| |-- Read: repo/GitHub state |
| +-- Stage writes (buffered) |
| |
+-----------------|------------------------+
|
+------------+------------+
| | |
MCP Gateway API Proxy Firewall
(tool auth) (LLM tokens) (egress control)
|
Safe Outputs Pipeline
|-- Allowlist (permitted write ops)
|-- Rate limits (max writes per run)
+-- Content sanitization
|
Central Audit Log
|
GitHub / Jira / Slack / etc.
Minimum Checklist Before Deploying Agents
- Isolated execution boundary: Agent runs in a separate container/VM with controlled egress
- No direct secret access: Secrets live in proxy/gateway — agent never sees them directly
- Approved tool gateways: Tool access through a trusted gateway, not directly
- Write buffering and moderation: Agent stages writes first; a pipeline vets content before actual writes
- Audit logs at all trust boundaries: Log at every communication point
- Do not rely on prompt instructions alone: Infrastructure controls, not "please don't do X" in the system prompt
Takeaway
"The future is not 'more powerful agents,' it is 'more governable agents.'"
When evaluating any agent platform, ask 4 questions:
- Do agents run in isolated environments?
- How are secrets protected — can agents see them directly?
- Are writes vetted and rate-limited?
- Are there audit logs at every trust boundary?
If the answer is "we trust the system prompt" — that's a signal the architecture needs redesigning.