Dapr Agents v1.0 GA: Production-Grade Runtime for AI Agent Workflows — From Prototype to Production
Dapr Agents v1.0 just reached General Availability (CNCF, March 23, 2026) — a milestone marking the shift of agent workflows from experiment to real production. Architecture analysis, comparison with LangGraph/CrewAI, production readiness checklist, and a decision framework for when to choose Dapr Agents.
Why GA Matters More Than You Think
GA (General Availability) is not just a marketing milestone. For infrastructure tools, GA has specific meaning:
- Stable API — no more surprise breaking changes
- Production support commitment from maintainers
- Completed security audit
- Backward compatibility guarantees
Dapr Agents v1.0 reached GA on March 23, 2026, announced through the Cloud Native Computing Foundation (CNCF). The signal: agent workflows are no longer a playground experiment — they're ready for enterprise production.
This is also a direct response to the "agent reliability gap" — the distance between impressive AI agent demos and AI agents that are actually trustworthy in production. Dapr Agents targets that gap directly.
What Is Dapr Agents?
Dapr Agents is a Python framework for orchestrating AI agent workflows, built on Dapr (Distributed Application Runtime). Built by the CNCF community.
The key difference from other AI agent frameworks:
Most AI agent frameworks (LangChain, CrewAI, AutoGEN) are designed from an ML/AI-first perspective — optimizing for model capabilities and chain logic. Dapr Agents is designed from an infrastructure-first perspective — optimizing for reliability, observability, and operational maturity.
This isn't better or worse — it's a different use case. Which framework fits depends on where you are in your journey.
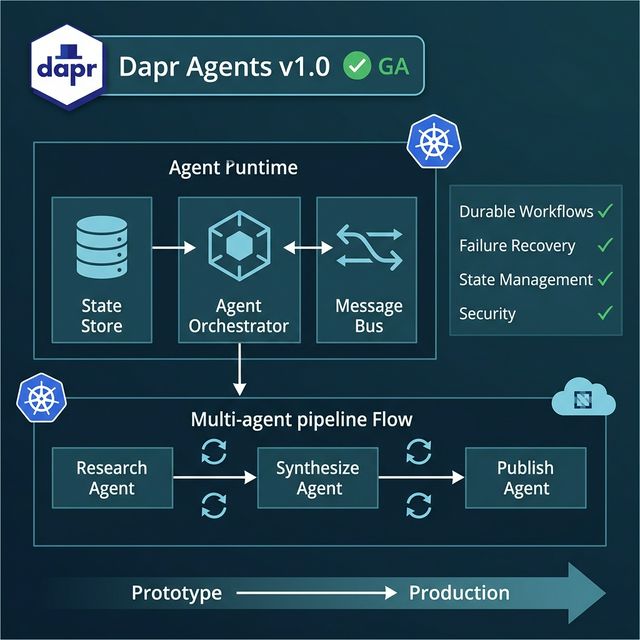
Conceptual Architecture
Three core components:
1. Agent Runtime
The engine that executes agent logic. Handles the run loop, task scheduling, and coordination between agents. Critically: the runtime is aware of conversation state — if it crashes and restarts, it can resume from the last checkpoint instead of starting over.
2. State Store
The persistence layer. Stores agent state, intermediate results, and conversation history. Built-in support for Redis, Azure CosmosDB, PostgreSQL, and many other backends (inherited from the Dapr ecosystem). The state store is the primary reason Dapr Agents can do durable workflows — the agent doesn't "die" when a pod restarts.
3. Message Bus / Coordination
The communication layer between agents in multi-agent setups. Not a simple function call — it's proper async messaging with guaranteed delivery. This enables multi-agent coordination that doesn't lose messages on a network blip.
Durable Workflows: The Key Differentiator
Durable workflow is the most important concept to understand about Dapr Agents.
With traditional agent frameworks:
Agent starts → executes → crashes → starts over ❌
With Dapr Agents durable workflows:
Agent starts → executes → crashes → resumes from checkpoint ✅
Real example: A 3-step agent pipeline (research → synthesize → publish). Step 2 runs for 45 minutes, then the server restarts due to a new deployment. With LangGraph/CrewAI: restart from step 1, 45 minutes of research is gone. With Dapr Agents: resume from step 2, step 1 results are preserved in the state store.
For long workflows (data processing, report generation, multi-source research), this property is more important than model intelligence.
Failure Recovery Patterns
Dapr Agents provides built-in patterns for the 3 most common failure types:
1. Transient network failures Built-in retry with exponential backoff. You don't need to implement retry logic manually for every external tool call.
2. Agent crashes / pod restarts State preservation via state store — agent resumes from last checkpoint.
3. Downstream service unavailability Circuit breaker pattern prevents the agent from continuously hammering a service that's down — instead it fails fast and routes to a fallback.
# Conceptual example — Dapr Agents workflow definition
@workflow
async def research_pipeline(ctx: WorkflowContext, input: PipelineInput):
# Step 1: Research (results saved to state store)
research = await ctx.call_activity(research_task, input=input.query)
# Step 2: Synthesize (runs from persisted research if step 1 is done)
synthesis = await ctx.call_activity(synthesize_task, input=research)
# Step 3: Publish (with built-in retry)
await ctx.call_activity(publish_task, input=synthesis,
retry_policy=RetryPolicy(max_attempts=3))
Production Readiness Checklist
Before deploying Dapr Agents to production, verify these points:
Observability
- Distributed tracing enabled (Dapr integrates with Jaeger, Zipkin, Azure Monitor)
- Metrics exported to monitoring stack (Prometheus/Grafana)
- Structured logging from agent runtime
- Alerting on workflow failure rates
Retry & Compensation
- Retry policies defined for all external service calls
- Compensation logic for non-retryable actions (delete, charge, send email)
- Dead letter queue for failed workflows
- Manual intervention path when circuit breaker triggers
Security
- mTLS between agents (Dapr provides this by default)
- Secret management via Dapr secret stores (no hardcoded API keys)
- Authorization policies between components
- Network policies limiting agent-to-agent communication scope
Cost Control
- Token usage metrics per workflow run
- Budget caps per agent (stop if threshold exceeded)
- Model tier routing (cheap model for simple tasks, expensive for complex reasoning)
- Async processing to avoid unnecessary concurrent runs
Dapr Agents vs Alternatives: When to Choose What
| Criteria | LangGraph / CrewAI | Dapr Agents |
|---|---|---|
| Best for | Experimentation, RAG, quick prototypes | Production multi-agent workflows |
| Learning curve | Low | Medium-High (requires Dapr knowledge) |
| Durability | Limited | Native (core feature) |
| State management | Manual | Built-in |
| Cloud-native ops | DIY | First-class |
| Community/ecosystem | Large | Growing (CNCF backing) |
| Team profile | ML engineers, data scientists | Platform engineers, cloud-native teams |
Simple decision:
- Researching or building a prototype → LangGraph/CrewAI
- Workflows longer than 5 minutes that need to reliably resume after failures → Dapr Agents
- Team has Kubernetes/cloud-native experience → Dapr Agents fits better
- ML-first team with less ops experience → LangGraph/CrewAI has less friction
Example Workflow Scenario
Multi-agent research pipeline:
Input: "Analyze competitive landscape Q1 2026"
Research Agent:
- Scrapes 15 sources (with retry on 429/503)
- State saved at each source → resume-safe
Synthesize Agent:
- Reads Research Agent output from state store
- Runs LLM synthesis in chunks (durable)
Publish Agent:
- Sends to Slack, saves to Notion
- Compensation: if Notion write fails, Slack message still sent
Total runtime: ~8 minutes
Fault tolerance: survives pod restart at any point
Quick-Start: Pilot Setup
Minimum prerequisites:
- Kubernetes cluster (local: kind or minikube works for testing)
- Dapr CLI installed
- Python 3.10+
Pilot steps:
# Install Dapr
dapr init --kubernetes
# Dapr Agents Python package
pip install dapr-agents
# Example workflows
git clone https://github.com/dapr/python-sdk
# Navigate to agents examples
Suggested first pilot (7 days):
- Choose 1 workflow currently running manually or with a simple LangChain setup
- Port it to Dapr Agents
- Inject 3 intentional failures (kill pod, disconnect network, rate limit an API)
- Measure: did it recover? How long?
- Compare with previous setup
Common Pitfalls
1. Over-automating too early Dapr Agents provides powerful orchestration — don't use it for simple single-step tasks. The complexity must be justified by a real reliability requirement.
2. Missing guardrails Durable workflows mean agents run longer. Without budget caps and rate limiting → cost surprises. Set explicit stop conditions and spending limits before going live.
3. Treating it as a drop-in replacement Dapr Agents requires thinking about workflows differently from LangGraph. State management is a developer responsibility — it needs careful design upfront.
Takeaway
Dapr Agents v1.0 GA is a clear signal: production AI agent orchestration is being standardized on cloud-native infrastructure.
It doesn't replace LangGraph or CrewAI — it serves a different use case: teams that need agent workflows with the durability, failure recovery, and operational maturity of production systems.
If you're building long-running agent workflows (>5 min), multi-agent coordination, or workflows where failure and resume are critical → evaluate Dapr Agents for your next project cycle.
CTA: Pick one existing workflow and build a 7-day pilot with Dapr Agents in staging. Measure reliability and cost against your current setup before committing.
Sources: AI Developer Tools Enter Autonomous Era: The Rise of Agentic Systems in March 2026 — DEV Community; Dapr GitHub